The Million-Token Lie
Why Your AI Can’t Actually Think About Long Documents

Imagine you’re an executive assistant. Fifty leadership meeting notes from the past year sit in front of you - a million tokens of context.
Your boss asks a reasonable question: “Find all the contradictions between what we decided in Q1 and the outcomes we reported in Q4.”
A token is roughly 3-4 characters of text. A million tokens is about 750,000 words - roughly 10 novels. A context window is how much text a model can “see” in a single conversation.
This isn’t a crazy ask. It’s exactly the kind of analysis humans do all the time, compare decisions to results, find where reality diverged from intention. But doing it well across 50 meetings? That’s genuinely superhuman. No person could hold all those threads, track every commitment against every outcome, without missing things. This is the AI superpower we were promised: turning the practically impossible into the routine.
You upload everything. A million tokens fits comfortably in that fancy new context window. You hit enter.
The model sees every word. Every decision. Every outcome. It has everything it needs. What happens next?

What Works, What Doesn’t
Here’s the thing: some tasks work fine.
“Find the API key in this config file.” No problem. “What did we decide in the March meeting?” Easy. “Summarize the Q2 budget discussion.” Done.
Simple retrieval. Simple summarization. The million-token window handles these just fine.
But the moment your task requires comparing things across the document (finding patterns, contradictions, relationships), performance doesn’t just degrade. It collapses.
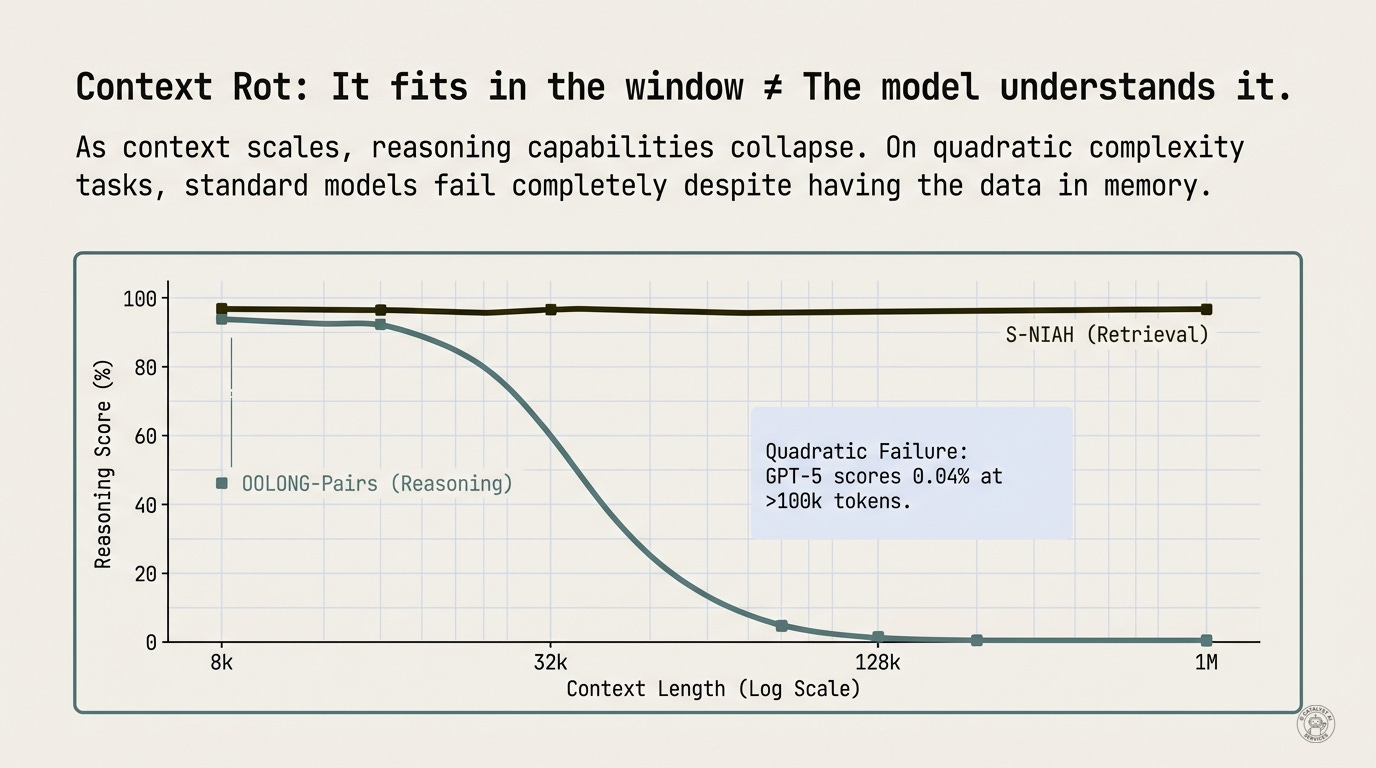
GPT-5, OpenAI’s current frontier model, scores 0.04% on comparison tasks at 100k+ tokens. That’s not a typo. Zero point zero four percent. Random guessing would do better.
And here’s what makes this dangerous: the model doesn’t return an error. It doesn’t say “I can’t do this.” It returns a confident, plausible-sounding answer. And it’s wrong.
The researchers call this context rot. The data is in the window. The capability isn’t. The model sees all the words. It cannot hold all the relationships. The context is rotting before the model can reason across it.
This is the million-token lie. Not that the context window is fake - it’s real. But for anything beyond simple retrieval, that context might as well not exist.
Why does this happen? The Transformer architecture underlying modern LLMs uses an attention mechanism that must attend to all tokens simultaneously. As context grows, attention weights spread thin - important tokens get less “focus.” Additionally, models exhibit position bias: information at the beginning and end of long contexts is retrieved reliably, but anything buried in the middle gets “lost in the middle”. The model may see all the words. It cannot hold all the relationships.
This explains why your “analyze this codebase” prompts return shallow observations. The model can see the code. It cannot reason across it.
The Fix
There’s a solution. It’s not bigger context windows. It’s a different architecture entirely - one that treats your document like a detective treats a case too large to hold in their head.
Back to those 50 meeting notes. A standard model tries to read all 50 meetings at once. It sees the words but can’t systematically compare every decision against every outcome - that’s 1,225 pairwise comparisons. The model’s attention spreads thin. It hallucinates contradictions that don’t exist and misses ones that do.
Now imagine the model works like a detective instead. Don’t read everything at once. Survey the scene, identify leads, interview witnesses one at a time, write everything down.
Same model, detective method: 58% accuracy.
The rest of this essay explains why this works, when to use it, and how you might already be using it without knowing. But the core insight is simple: stop treating context as something to read. Start treating it as something to investigate.
The Complexity Gap
Not all context tasks are created equal. Understanding why context rot happens requires understanding what kind of problem you’re actually asking the model to solve. The classification determines everything.
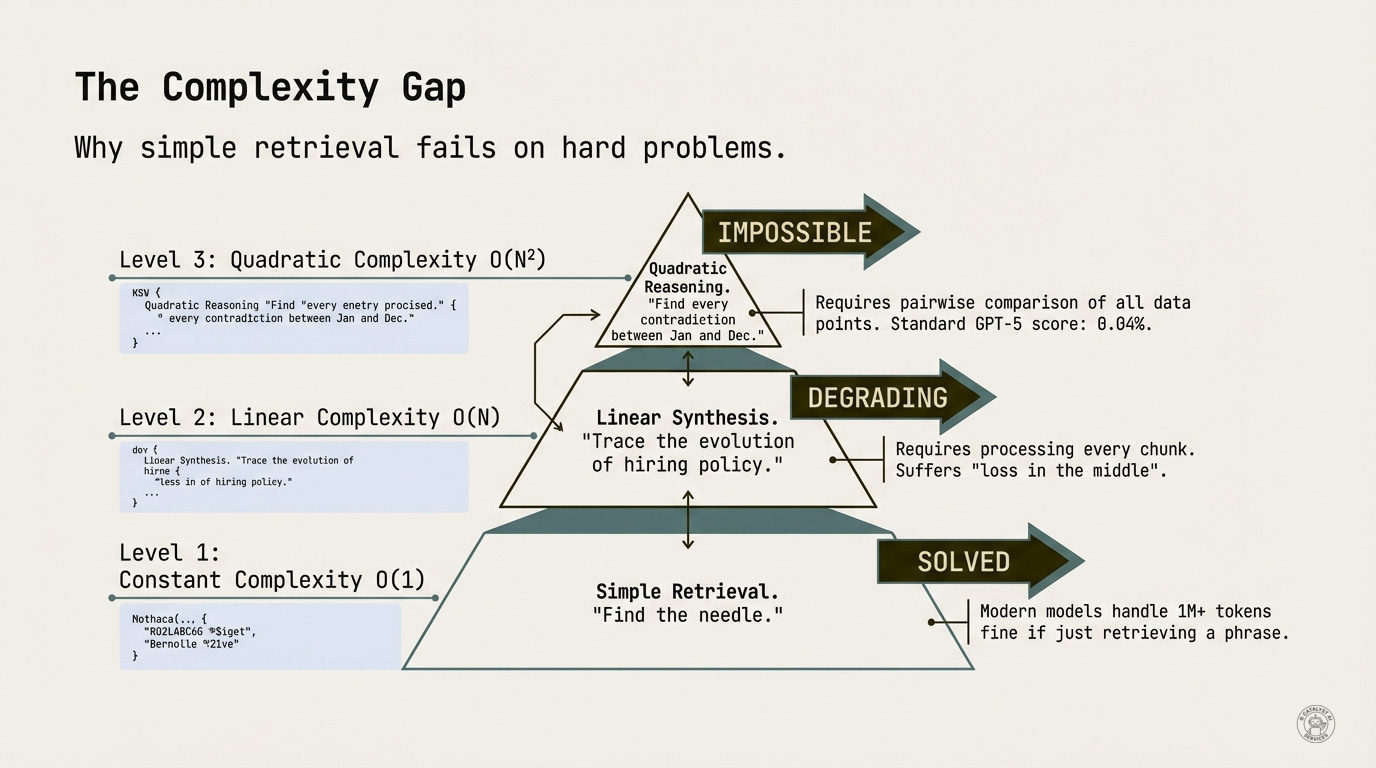
Level 1: Retrieval O(1) - “Find the API key in this config file.” Solved. This is what RAG (Retrieval-Augmented Generation) does well - locate a specific piece of information and return it. The Needle in a Haystack benchmark tests exactly this, and modern models handle 1M+ tokens fine if just retrieving a phrase.
Level 2: Synthesis O(N) - “Trace the evolution of hiring policy.” Degrading. You need to read everything once. Requires processing every chunk. Suffers from “lost in the middle” - models reliably recall information at the beginning and end of long contexts but struggle with anything buried in the center.
Level 3: Reasoning O(N²) - “Find every contradiction between Jan and Dec.” Impossible. You need to compare every statement against every other statement. The combinatorial explosion breaks the architecture. Recent research proves this isn’t just empirical - two-layer transformers cannot solve even two-hop reasoning; the minimum architecture requires three layers. Standard GPT-5 scores 0.04%.
The million-token context window solves Level 1. It struggles with Level 2. It fails completely at Level 3. The LongBench v2 benchmark confirms this: the best-performing model achieves only 50.1% accuracy on long-context reasoning tasks.
And Level 3 is where the actual value lives. Reasoning across large contexts (finding patterns, contradictions, implications) is what humans hire analysts to do. It’s what due diligence requires. It’s what actual intelligence looks like.
Do You Actually Need This?
Before you conclude your AI tools are broken, let’s be honest about use cases. Most users don’t need RLM architecture - if your documents fit comfortably in a 200k context window and you’re asking straightforward questions, standard approaches work fine. Your documents under 100k tokens, doing retrieval or simple summarization, latency matters more than depth? Standard models are your friend.
But if you’re working with 500k+ token corpora - legal discovery, research synthesis, codebase audits - and your task requires comparing elements across the full document to find contradictions, patterns, or relationships where accuracy matters more than speed? That’s when RLM architecture becomes relevant. This is specialized architecture for the long tail of enterprise and research use cases, not a replacement for everything.
How to Test This Yourself
Want to know if context rot is affecting your use case? Run this diagnostic:
Step 1: Retrieval baseline Ask a needle-in-haystack question: “What is the value of X on page 47?” or “Find the function named handleAuth.”
If this fails, your problem isn’t context rot - it’s something more basic.
Step 2: Synthesis stress test Ask an O(N) question: “Summarize all mentions of budget across this document” or “List every error handling pattern in this codebase.”
Watch for: incomplete answers, “lost in the middle” gaps, hallucinated items.
Step 3: Reasoning stress test Ask an O(N²) question: “Find any contradictions between sections” or “Which functions call each other but have incompatible return types?”
If Step 1 works but Step 3 fails catastrophically, you’ve found context rot. That’s when RLM architecture becomes relevant.
The Paradigm Shift: Context as Environment
The breakthrough (the key insight from the MIT research) comes from a simple reframe that changes everything: stop treating the context as something to read. Start treating it as something to query.
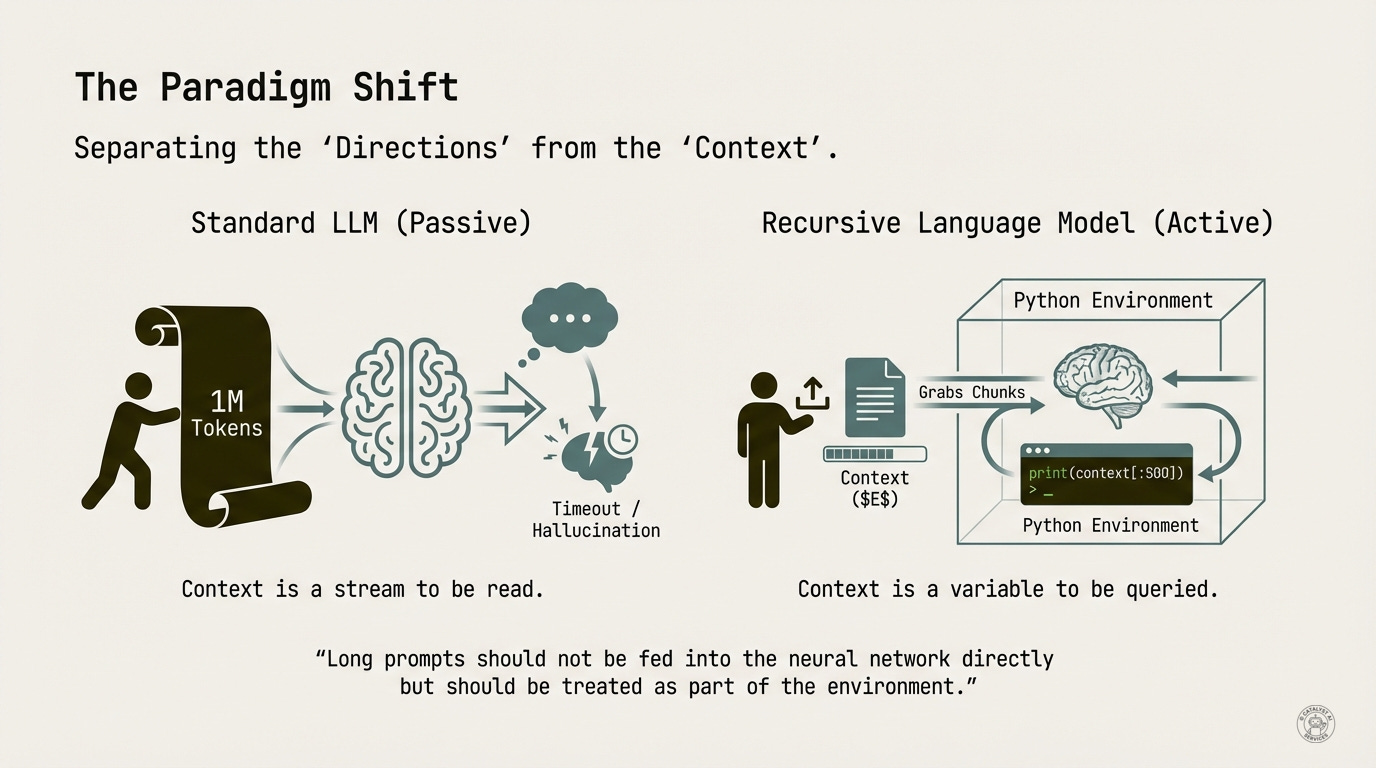
On the left: the standard approach. Cram 1M tokens into the context window. Hope the model’s attention mechanism can handle it. Watch the model timeout or hallucinate.
On the right: the Recursive Language Model approach. The document becomes a variable in a Python environment. The model writes code liken print(context[:500]) to explore it. It grabs chunks selectively. It never tries to hold everything in working memory at once.
The key quote from the research: “Long prompts should not be fed into the neural network directly but should be treated as part of the environment.”
This is the same insight that drove out-of-core algorithms in the 1960s. When your dataset doesn’t fit in RAM, you don’t buy more RAM (or wait for Moore’s Law to save you). You design algorithms that stream through the data intelligently. Research on recurrent memory proves the point: GPT-4 fails at its full 128K context window, but a small model augmented with external memory generalizes to 11 million tokens.
RLMs do for reasoning what out-of-core did for computation: they make the problem tractable by changing the architecture, not the hardware. Doctrine over tools - the method matters more than the model size.
The Detective Method
The paper describes emergent patterns in how RLMs tackle problems: filtering via code, recursive sub-calling, answer verification, output stitching. I’ve distilled these into a five-step workflow I call the detective method - a pedagogical framework for understanding what’s actually happening.
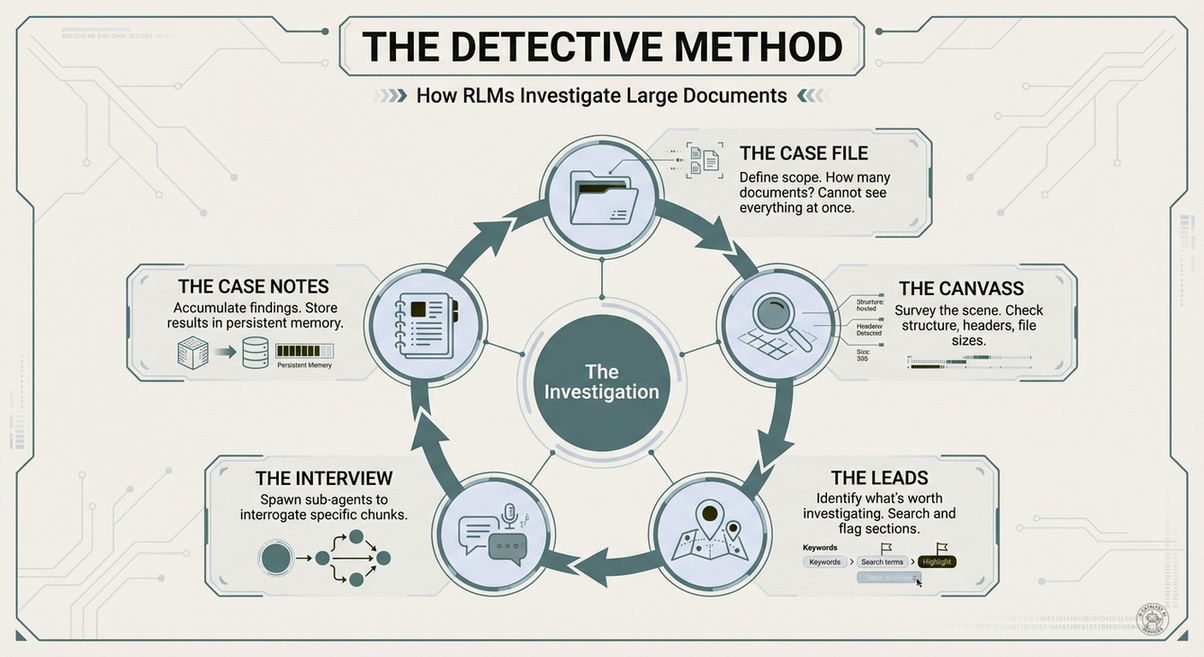
1. The Case File - You can’t interview every person in the city. Start with what you know: the scope of the investigation. How many documents? What time period? What’s the structure? The agent is explicitly prevented from reading everything at once - this forces strategic thinking.
2. The Canvass - Survey the scene before diving in. The agent peeks at the first few hundred characters, lists section headers, checks file sizes. What kind of document is this? Meeting notes? Legal filings? Code? Orient before committing.
3. The Leads - Identify what’s worth investigating. The agent uses search and pattern-matching to find relevant sections - not reading everything, but flagging where the interesting stuff lives. Cut the haystack into manageable piles.
4. The Interview - Ask focused questions. The agent spawns sub-instances of itself, each one interviewing a specific “witness” (document chunk). Each sub-agent has a narrow focus: “What decisions were made in this meeting?” The answers come back to the lead detective for synthesis.
5. The Case Notes - Accumulate findings. As interviews complete, results are stored in a persistent “notebook” - not in the agent’s memory, but in an external variable. This is critical: without persistent storage, sub-agent outputs evaporate. The notebook holds all the fragments until the final report is assembled.
The Meeting Notes Case, Revisited
Remember the executive assistant scenario? 50 meetings, 1,225 pairwise comparisons, 0.04% accuracy with standard approaches. Now the part I held back: what actually happens inside each step.
The Interview phase is where the magic happens. Each sub-agent gets a narrow focus - one decision, one question: “Does any outcome contradict this?” The sub-agent isn’t trying to be smart about the whole corpus. It’s doing one comparison with full attention. That’s the key insight: you trade breadth for depth, then aggregate.
The Case Notes aren’t optional - they’re load-bearing. Each interview result is appended to a running list: findings.append(result). The agent doesn’t try to remember anything - it writes everything down in an external variable. Without this, sub-agent outputs evaporate between calls. The notebook is what makes synthesis possible.
Synthesis is a separate phase. The lead detective reviews the case notes, not raw interviews. Contradictions are compiled with citations. The final report is accurate because each comparison was made with full attention - not diluted across a million tokens.
The root model never sees the full document. It only sees the outputs of its own investigation. This is how you reason across 10 million tokens: you don’t. You run an investigation with focused interviews and aggregate the findings.
The Proof: Crushing the Quadratic Ceiling
Theory is nice. Results matter. Let’s look at what the benchmarks actually show.

BrowseComp+: Navigate 1,000 documents (8.3M tokens) to answer questions - base models can’t even attempt it
OOLONG: Aggregate information scattered across a long document (O(N) complexity)
OOLONG-Pairs: Find relationships between pieces of information (O(N²) complexity)
CodeQA: Answer questions about large codebasesT
he numbers speak for themselves. These benchmarks test long-context reasoning at different complexity levels:
On the OOLONG-Pairs benchmark, a quadratic complexity task requiring comparison across large contexts, standard GPT-5 scores 0.04%. Literally random guessing. Summary agents don’t help (0.01%).
The same model, wrapped in an RLM architecture, scores 58%.
That’s not a 2x improvement or a 10x improvement. Do the math: 58 divided by 0.04 is 1450x. From random chance to majority correct. From useless to useful.
The architecture is the capability. Same weights, same training, same model. Different interface to the problem. Completely different results. If that doesn’t make you reconsider what “model capability” actually means, I don’t know what will.
The Honest Trade-off: Latency
Let me be direct about this: RLMs aren’t magic. They’re a trade-off, and you need to understand what you’re signing up for.

RLM queries take significantly longer than standard queries. The researchers note latency is “heavily dependent on implementation details,” but the pattern is clear: recursive decomposition means more API calls, more code execution, more round-trips. Complex documents spawn complex decomposition trees. Expect minutes, not seconds, for hard problems.
Why? Because the model is doing more work. It’s writing code, executing it, calling sub-instances, aggregating results. Each recursive call costs time.
USE FOR: Reports, Audits, Due Diligence, Research Synthesis
NOT FOR: Chatbots, Real-time, Interactive
Know what you’re building. Choose the right tool.
The latency may also be a feature. If your task genuinely requires reasoning across a million tokens, maybe it should take 15 minutes. The alternative - pretending you did the analysis in 30 seconds - is worse than useless. It’s confidently wrong.
The Cost Paradox
Counter-intuitively, RLMs can be cheaper than standard approaches despite running more compute cycles.
Why? If you feed 10 million tokens into a standard model, you pay for processing all 10 million tokens. An RLM might scan the text with Python (free), extract only the 50,000 relevant tokens, and process those. The model filters before it reasons. You pay for signal, not noise.
The research found RLM queries often cost 30% less than brute-force long-context calls. The catch: high variance. Median cost is low, but pathological runs can spiral. Set a max_steps timeout.
When RLMs Fail
Now for the honest part that most hype articles skip: RLMs trade context rot for a different failure mode. I call it decomposition blindness, and you need to understand this before betting your analysis pipeline on recursive architecture.
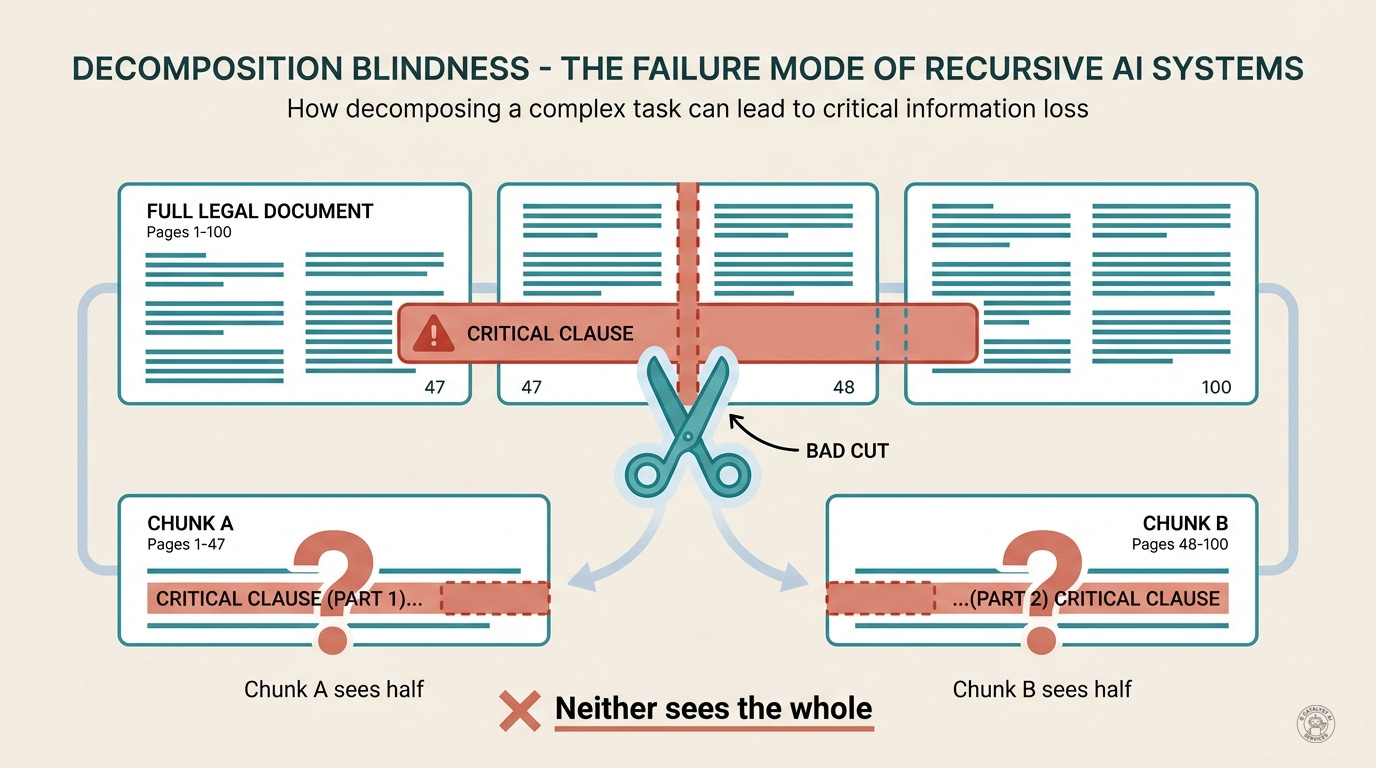
The Leads phase doesn’t always identify the right sections. If your chunking strategy splits a paragraph in half, or separates a question from its answer, or divides a function from its critical comment - the Interview calls will each miss the connection. The sub-agents see their chunks perfectly. They just can’t see what fell between the cracks.
Common failure patterns:
Bad cuts - The agent splits a legal contract by page breaks, but a critical clause spans pages 47-48. Neither chunk contains the full clause. The analysis misses it entirely.
Missing cross-references - Document A defines a term. Document B uses it. If the Leads phase processes them separately and the Interview calls don’t know to look for the definition, the reasoning breaks silently.
Aggregation collapse - Each sub-agent returns a partial answer. The synthesis phase fills with fragments. But the final aggregation step has its own context limit. If you’ve generated more partial answers than fit in the synthesis window, you’ve just moved the problem.
Silent confidence - The scariest failure. The agent completes successfully, returns a coherent answer, and is wrong because the recursive structure never found the right piece. Unlike context rot (which often produces obvious gibberish), decomposition blindness produces plausible-sounding errors.
[Aside: The researchers documented something fascinating: models get anxious when they can’t see the text. Agents sometimes found the correct answer, verified it multiple times, then discarded it and generated a wrong answer from scratch. They doubt themselves when blindfolded. Some models enter pathological verification loops, re-checking work obsessively. The architecture gives them power but also uncertainty.]
Mitigations:
Overlap your chunks. Don’t cut at exact boundaries - include context from adjacent sections.
Use semantic chunking, not character counts. Split at paragraph or section boundaries.
Verify critical findings with targeted follow-up queries. “You said X contradicts Y - show me both passages.”
For high-stakes analysis, run multiple decomposition strategies and compare results.
RLMs aren’t a silver bullet - they’re a different set of trade-offs with different failure modes. The question isn’t “is this better?” but “what kind of problem am I solving, and which failure mode am I more willing to tolerate?” Know your terrain.
You’re Already Using This: Claude Code & Cowork
If you’re using Claude Code or Claude’s cowork mode, you’re already using RLM principles - you just might not have the vocabulary for what’s happening.
Watch what happens when you ask Claude Code to “find all the places where we handle authentication errors in this codebase”:
Case File - Claude doesn’t try to paste your entire repo into context. It can’t see everything at once. It starts by understanding the scope: how many files? What’s the structure?
Canvass - It runs
grepandglobto survey the scene. What files exist? What patterns match? Where does “auth” appear?Leads - It identifies relevant files and reads them selectively. Not the whole codebase - just the authentication modules worth investigating.
Interview - For complex analysis, it spawns sub-agents. The Task tool lets it delegate focused questions to specialized workers: “What errors does this file handle?”
This isn’t accidental. It’s the same architecture the RLM paper describes. The difference between Claude being useful on a 100-file codebase versus hallucinating isn’t model intelligence - it’s environmental design.

Claude Code implements RLM principles. The REPL (Read-Eval-Print Loop - the interactive programming environment) is your terminal. The Task tool functions like the paper’s llm_query() - spawning focused sub-agents. The “case file constraint” is the fact that Claude can’t actually see your files until it explicitly reads them. It’s not a pure RLM implementation (the constraints are behavioral, not architectural), but the patterns are the same.

When cowork mode feels like magic, when it correctly traces a bug across twelve files you never mentioned, that’s the detective method in action. Canvass the structure, identify leads, interview relevant chunks, aggregate the findings.
The implication for how you work: don’t paste your whole codebase - let Claude navigate to what it needs. Use explicit file references (@file) to guide the canvass phase. Trust the decomposition when Claude spawns sub-tasks; it’s doing what the research says works. And expect latency on hard problems, because a 10-minute analysis that’s correct beats a 30-second hallucination every damn time.
The “AI coding assistant” framing undersells what’s actually happening here. You’re not using a chatbot with code access. You’re using a recursive reasoning system with your codebase as its environment. Once you see it that way, everything about how you work with these tools changes.
The Future: Inference-Time Compute
We’ve spent years optimizing prompts: choosing words carefully, crafting system instructions, engineering the input. Prompt engineering has been the dominant paradigm. But RLMs suggest a different frontier entirely.
The real unlock is inference-time compute - the idea that model capability isn’t just about training (what the model learned) but about what happens during each query (how the model reasons through the problem). This is where the leverage actually lives.
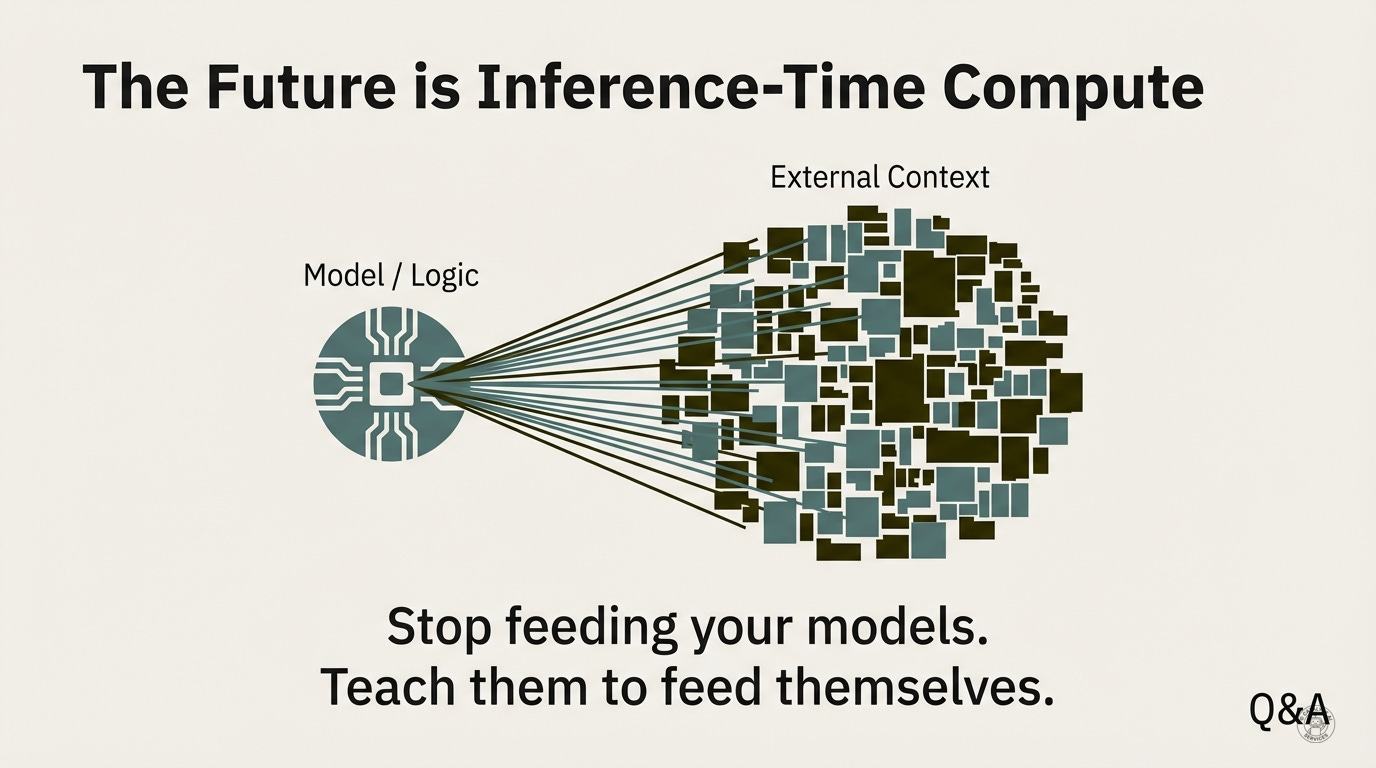
The capability of an LLM is limited by its context window. The capability of an RLM is limited only by the tools you give it access to.
“Stop feeding your models. Teach them to feed themselves.”
What if the model could:
Query databases directly instead of having schemas pasted in?
Browse documentation interactively instead of having it summarized?
Execute code against live systems instead of reasoning about hypotheticals?
This is the trajectory. Not “bigger context windows” but “richer environments.” Not “more tokens” but “better tools.”
The models that win won’t be the ones with the largest context. They’ll be the ones with the most sophisticated environmental interfaces.
What This Means For You
If you’re building with LLMs, the recalibration is simple: stop trusting context window marketing. Test reasoning tasks, not retrieval tasks. Measure what actually matters for your use case.
Monday morning actions:
Run the three-step diagnostic from earlier on your most important long-context workflow. Does it pass retrieval but fail reasoning? You’ve found context rot.
If your task is O(N²) (comparison, contradiction-finding, pattern-matching across large documents), standard approaches will fail. Start exploring recursive architectures.
Accept the latency trade-off. A 10-minute analysis that’s correct beats a 30-second hallucination. Every time.
If you’re using Claude Code already: work with its RLM patterns. Don’t paste your codebase - let Claude navigate to what it needs. Don’t summarize documents - let Claude query them. Trust the decomposition when it spawns sub-tasks.
The million-token context window was a lie. There’s a better architecture. It requires rethinking how you build - and that’s always harder than buying more tokens.
Links & Resources
Primary Research: - Zhang, Kraska, & Khattab - “Recursive Language Models: A New Inference Paradigm for Arbitrarily Long Contexts” (MIT CSAIL / Stanford, 2025)
Concepts Explained:
Token: A unit of text (~3-4 characters). 1M tokens ≈ 750,000 words ≈ 10 novels
Context Window: The maximum text a model can “see” in a single conversation
Context Rot: The phenomenon where models fail on reasoning tasks despite having all data in the context window - performance degrades even within valid limits
Attention Mechanism: The system inside transformer models that decides which tokens to focus on when generating each response
O(N²) Complexity: Tasks where every element must be compared to every other element (e.g., finding contradictions)
RAG: Retrieval-Augmented Generation - finding and returning specific information from a knowledge base
Out-of-core Algorithms: Computing techniques from the 1960s for processing datasets larger than available RAM
OOLONG Benchmark: Evaluation suite for long-context reasoning, including linear (synthesis) and quadratic (comparison) complexity tasks
Inference-Time Compute: Capability that emerges from how the model reasons during a query, not just what it learned during training
Detective Method: My pedagogical framework (Case File → Canvass → Leads → Interview → Case Notes) for understanding RLM patterns
Tools Mentioned: - Claude Code - Anthropic’s terminal-based agentic coding tool (implements RLM patterns) - Cowork - Claude’s file-system-enabled work mode for complex tasks without coding
Related Reading:
Attention Is All You Need - The transformer architecture that created the context window constraint
Lost in the Middle - Research showing models struggle with information in the middle of long contexts
Needle in a Haystack - Greg Kamradt’s foundational benchmark for O(1) retrieval testing
LongBench v2 - Comprehensive long-context benchmark; best models achieve only 50.1% accuracy (Dec 2024)
How Do LLMs Perform Two-Hop Reasoning in Context? - Proves two-layer transformers cannot solve two-hop reasoning; minimum three layers required (2025)
Do Large Language Models Latently Perform Multi-Hop Reasoning? - Evidence of latent reasoning pathways in transformer models (ACL 2024)
In Search of Needles in a 11M Haystack - GPT-4 fails at full 128K context; recurrent memory generalizes to 11M tokens